Jedním z nástrojů, bez kterých už bych se při překládání asi neobešel, jsou korpusy, a především Český národní korpus. Co to vlastně ten korpus je? Nejvíc se mi líbí žertovná definice anglického lingvisty Geoffreyho Leeche, „a helluva lot of text, stored on computer“ (řekněme „fůra textů uložených v počítači“). Podrobnější poučení najdete například tady. Podstatný je ale fakt, že v tom kvantu textů můžete vyhledávat pomocí speciálních nástrojů a zjišťovat, jak se jazyk chová, co je v jazyce typické a co okrajové. Podle toho pak při překládání můžete dělat lepší rozhodnutí a můžete si svá řešení také obhájit exaktními čísly.
První korpusy v 60. letech 20. století měly velikost asi milion slov (řekněme necelé 4000 normostran). Dnes ty největší, „institucionální“, čítají miliardy slov. Ty nejlepší jsou navíc pro daný jazyk reprezentativní a jsou „označkované“: v jejich útrobách jsou uloženy lingvistické informace, díky nimž například zadáte základní tvar slovesa hnát a program najde i tvary hnaly, ženeš nebo ženoucí (a teoreticky i přechodník žena). Nebo můžete vyhledat všechny výskyty zájmena ten následované přídavným jménem ve 3. stupni, a to ve všech tvarech (např. těmi nejdelšími, tu nejvzdálenější). Program nalezená slova/jevy zobrazí ve výpisu, kterému se říká konkordance. Co řádek, to jeden výskyt. Hledané slovo vidíte zvýrazněné uprostřed a kolem něj je i nejbližší kontext. To ale zdaleka není všechno…
Obrázek. Konkordance tvarů slova hnát v korpusu SYN2015 (celkem 3120 výskytů)
Jestli patříte mezi překladatele, kteří zatím korpusy nepoužívají, a předchozí dva odstavce vás nechaly chladnými, možná se vám zrychlí tep, když řeknu, že kromě jednojazyčných korpusů existují i korpusy vícejazyčné a konkrétně korpusy paralelní. Do nich zadáte slovo nebo slovní spojení v jednom jazyce a program zobrazí věty, kde se vyskytuje, i s odpovídajícími větami v druhém jazyce. Můžete tak zjistit, jak se určité slovo, slovní spojení nebo jev překládá do druhého jazyka.

Obrázek. Konkordance spojení out of the blue v anglicko-české části korpusu InterCorp
Čeští překladatelé (a všichni, kteří pracují s jazykem) mají obrovskou výhodu díky tomu, že na půdě Filozofické fakulty vznikl Český národní korpus, který je dnes na špičkové úrovni a po registraci je k dispozici komukoliv a zdarma. Vlastně to není jeden jediný korpus, ale pořádně velká a stále se rozrůstající rodinka korpusů. V ČNK najdete především korpusy jednojazyčné české (psaného jazyka, mluveného jazyka, historické češtiny atd.), ale i korpusy dalších jazyků. A také to, co nejspíš bude překladatele zajímat nejvíc: mnohojazyčný paralelní korpus Intercorp, který ve verzi 9 obsahuje celkem 39 cizích jazyků. Kromě korpusů nabízí ČNK i několik dalších užitečných nástrojů, které z korpusových dat vycházejí.
Možností, jak využít ČNK, je opravdu mnoho, podívejme se proto, co se nejvíc osvědčilo mně.
1. Hledání v jednojazyčných korpusech (nebo v jedné složce paralelního korpusu)
Zvažuji překladatelské řešení. Používá se? Používá se často, nebo jenom tu a tam?
Příklad: Dělám po kolegovi korekturu a nezdá se mi spojení spojení zářný důkaz. Po pěti hodinách korektur už ztrácím soudnost. Opravdu se to spojení používá?

Obrázek. Konkordance spojení zářný důkaz v jednojazyčném korpusu SYN2015
Výsledek: čtyři výskyty v korpusu o velikosti 100 mil. slov nesvědčí o tom, že by šlo o obvyklé spojení, když se např. spojení přesvědčivý důkaz ve stejném korpusu vyskytuje 108krát
Zvažuji dvě překladatelská řešení. Které z nich je častější, typičtější?
Příklad: Je častější spojení s třetím, nebo se třetím?

Obrázek. Konkordance s třetí v korpusu SYN2015 (96 výskytů) – dotaz zněl: [word=“s“ & tag=“R.*“][lemma=“třetí“], tzn. předložka s následovaná kterýmkoliv tvarem slova třetí

Obrázek. Konkordance se třetí v korpusu SYN2015 (86 výskytů) – dotaz zněl: [word=“se“ & tag=“R.*“][lemma=“třetí“], tzn. předložka se následovaná kterýmkoliv tvarem slova třetí
Výsledek: používá se obojí, ale varianta s je o něco častější.
S jakými jinými slovy se určité slovo pojí?
Mám to slovo na jazyku… Jaká slova se nejčastěji vyskytují před slovem důkaz? Nejprve vytvoříme konkordanci hledaného slova a potom v záložce Kolokace necháme vypočítat seznam kolokací v určité pozici, např. na první pozici vlevo (tj. -1 až -1).
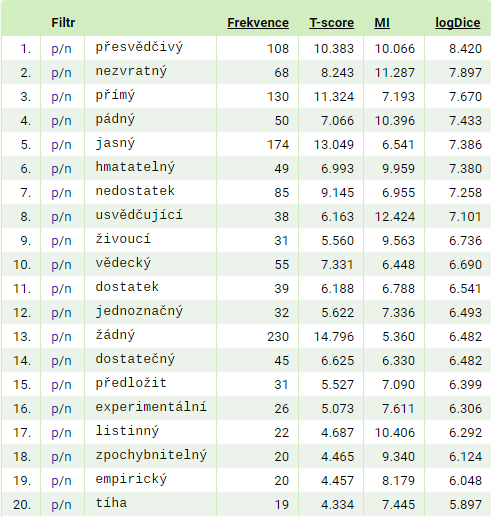
Obrázek. Kolokace slova důkaz v korpusu SYN2015 – top 20
Poznámka: jestliže s korpusem začínáte, s jednotlivými ukazateli si hlavu nelámejte. Jen zkuste, jak se změní pořadí kolokací, když je seřadíte podle jiného ukazatele.
2. Hledání v paralelních korpusech
Jak se určité slovo nebo slovní spojení překládá? Toto základní vyhledávání v paralelním korpusu jsme si už ukázali. Hledat ale můžeme ve kterémkoli z 39 jazyků v kombinaci s češtinou a často i navzájem. Překládáme např. nepříliš dobrý anglický překlad ze španělštiny a narazíme na podezřelé spojení publicity revenues. Naštěstí máme i španělský originál, a tak najdeme, že ve španělštině je na inkriminovaném místě ingresos publicitarios. Zadáme dotaz do korpusu a lusknutím prstu máme odpověď: českým ekvivalentem je spojení příjmy z reklamy (a v angličtině asi mělo být advertising revenue(s)).
 Obrázek. Konkordance spojení ingresos publicitarios ve španělsko-české části korpusu InterCorp
Obrázek. Konkordance spojení ingresos publicitarios ve španělsko-české části korpusu InterCorp
3. Další nástroje
Treq
Jakými ekvivalenty se do jiného jazyka překládá určité slovo? Nástroj Treq zobrazí (prozatím jednoslovné, v budoucnu i víceslovné) ekvivalenty, které v paralelních korpusech odpovídají zadanému slovu. Vše je vypočítané statistickými metodami, proto zejména v nižších polohách najdete i slova, která neodpovídají. Když se ale podíváte na nejvyšší příčky, nechce se vám věřit, že ekvivalenty našel stroj. Myslím, že Treq ocení i tlumočníci v kabině (a díky chytrému telefonu možná i na poli, i když pro ty by to chtělo nějakou jednoduchou aplikaci).

Obrázek. Nástroj Treq: české ekvivalenty anglického slova blue.
Všimněte si sloves zmodrat a modrat, ale také slova zčistajasna – když slovo rozkliknete, dostanete se do paralelního korpusu, kde uvidíte, že toto příslovce je překladem spojení out of the blue.
SyD
Který z dvou či více konkurentů (slov či slovních spojení) je češtině častější? Na takovouto otázku nám nejrychleji odpoví nástroj SyD.

Obrázek. Rozhraní nástroje SyD. Která forma je častější: Stevea, nebo Steva?
Několik upozornění
Na tomto místě bych měl upozornit na několik věcí.
Upozornění první: v korpusech je autentický jazykový materiál, ve kterém není nouze o chyby a neobratnosti. Proto když něco v korpusu najdeme, nemusí to ještě znamenat, že je to správně. Například správný tvar slovesa dokázat zní ve 3. osobě množného čísla dokážou. Zkuste si do SyDu zadat správné dokážou a nesprávné dokáží a podívejte se na statistiky výskytů!
Upozornění druhé: v korpusech ČNK jsou stovky milionů slov a v souhrnném korpusu současné češtiny SYN (verze 4) jich je 3,63 mld. Jsou to tedy opravdu velké korpusy, bylo by ale bláhové domnívat se, že v nich je všechno, co kdo kdy napsal.
Upozornění třetí: nezapomínejme na homonymii, tzn. že některé tvary dvou či více různých slov vypadají zcela totožně, např. stát může být podstatné jméno, anebo infinitiv slovesa. Proto když chceme srovnávat, jak časté je slovo země oproti slovu stát, a neupřesníme, že hledáme jen podstatné jméno stát (dotaz bude znít např. [lemma=“stát“ & tag=“N.*“]), a ne infinitiv slovesa stát, srovnáváme jablka s hruškami.
Pokud chceme z hledání v korpusech vytěžit maximum, je dobré naučit se základní pravidla vyhledávání včetně základů dotazovacího jazyka CQL (v něm je zapsaný právě výše uvedený příklad, dotaz na podstatné jméno stát). Vůbec to není těžké – pomůže vám v tom srozumitelně napsaná wikipedie Českého národního korpusu.
Korpus je bomba
Mám teorii. Překladatelé jsou často humanitně založení lidé, kteří technické novinky nevítají s otevřenou náručí. Když ale zjistí, co všechno jim korpusy můžou nabídnout, bývají nadšeni. Jednou jsem udělal komorní školení o Českém národním korpusu pro skupinku kolegyň a jednoho kolegu. Potom od našeho miniškolení uplynulo několik měsíců a už to vypadalo, že můj výklad nepadl na příliš úrodnou půdu. Vtom ale napsala na Facebook Lucie Mikolajková, jedna z účastnic našeho miniškolení: „Vyhledávání v Český národní korpus je naprostá bomba. Tvůrcům patří má nehynoucí vděčnost.“ Zareagoval jsem: „Já jsem tam přihlášený skoro nonstop,“ a Lucie odpověděla: „Kvalita a bohatost mých českých výplodů stoupá úměrně s mou schopností používat CQL. :-)“ Když takto korpusy chválí jedna z nejlepších současných překladatelek, jistě pomůžou i ostatním překladatelům (a možná i tlumočníkům).
Technická poznámka: redakční systém tohoto blogu automaticky mění rovné uvozovky na „kudrnaté“, do ČNK je ale třeba zadávat uvozovky rovné. Proto budete-li dotazy z tohoto článku kopírovat do dotazu v ČNK, nezapomeňte uvozovky změnit na rovné (stačí stisknout klávesu s uvozovkami).
K některým funkcím ČNK a k formulaci dotazů se v tomto blogu určitě vrátím. V jednom z dalších příspěvků také ukážu, jak si můžete v počítači vytvořit svůj vlastní malý korpus.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Komentář vložíte zde.
Chcete-li vložit komentář, musíte se přihlásit.