
Už jsme si ukázali, jak se pracuje s Českým národním korpusem, ale co když si chce překladatel vytvořit svůj vlastní malý korpus a chce jej prohledávat přímo ve svém počítači? Půjde nejspíš o texty z určité omezené tematické oblasti, třeba o smlouvy nebo o články z oblasti životního prostředí, ale může to být i kniha nebo knihy určitého autora.
Vytvořit si takový korpus a pracovat s ním už dnes není vůbec žádný problém. Existuje totiž několik programů, tzv. korpusových manažerů, které dokážou z textů uložených v počítači vytvořit jak konkordanční řádky ve formátu KWIC (key word in context – viz obrázek nahoře), tak frekvenční seznamy slov. Jen se musíme smířit s tím, že v těchto jednoduchých programech budeme pracovat jen se „surovým“ textem, tzn. že text nemáme označkovaný a lemmatizovaný. Proto když zadáme slovo speak, program najde právě jen tvar speak, a nikoliv speaks nebo spoke. Pokud ale korpus používáme jen jako referenční pomůcku, vůbec to nevadí, zvlášť u angličtiny a řady dalších jazyků – můžeme totiž zadat všechny možné tvary nebo chytře použít zástupný znak, většinou hvězdičku: pomocí speak* sice nenajdeme spoke, ale najdeme speak, speaks a speaking (ale také speaker).
Příprava textů
Nejdřív samozřejmě musíme připravit text nebo texty v elektronické podobě, konkrétně ve formátu TXT. Kde vezmeme vhodné texty? Možnosti jsou následující:
• texty z počítače,
• texty postahované z webu – manuálně nebo pomocí speciálního stahovacího programu,
• texty převedené do formátu TXT z překladové paměti (např. pomocí prográmku SDLTmConvert),
• texty převedené pomocí programů pro optické rozpoznávání znaků (OCR) z naskenovaných dokumentů včetně knih,
• e-knihy převedené např. programem Calibre
• a určitě vymyslíte i další možnosti.
Právní upozornění: díla chráněná autorským zákonem můžeme používat pro vlastní potřebu (§ 30 autorského zákona), pokud je ale bez licence šíříme nebo „sdělujeme veřejnosti“, tedy například je umístíme na internet, porušujeme zákon. Zákon porušíme i tehdy, když např. prolomíme ochranu DRM (viz § 43 autorského zákona).
Pokud jde o formát textů, je důležité vědět, že každý korpusový manažer vyžaduje určité kódování – UTF-8, Unicode, ANSI… Proto je potřeba text přeuložit (např. v poznámkovém bloku nebo v PSPadu) podle konkrétního programu ve správném kódování, případně postupovat metodou pokus-omyl.
Korpusové manažery
A pak už přichází ke slovu korpusový manažer. Osobně mám zkušenost s dvěma bezplatnými a s jedním zpoplatněným:
• AntConc (a jeho bratříček AntPConc, který je určen pro paralelní korpusy – o tom někdy jindy),
• TextSTAT,
• WordSmith Tools – korpusový manažer používaný v zahraničí na mnoha vysokých školách, který zvládá i větší korpusy (cena 50 liber).
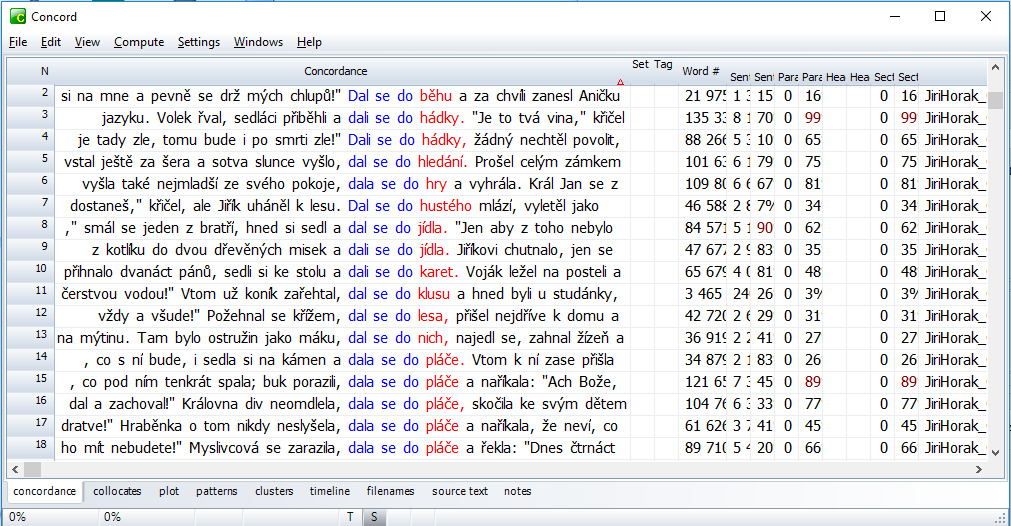 Obrázek. Konkordance spojení dal* se do z textu knihy Jiřího Horáka České pohádky (program WordSmith Tools)
Obrázek. Konkordance spojení dal* se do z textu knihy Jiřího Horáka České pohádky (program WordSmith Tools)
Angličtináři mi asi dají za pravdu, když řeknu, že v anglických textech se nejvíc cituje ze Shakespeara a z Bible. Víte, že obojí snadno stáhnete ze stránek Project Gutenberg? Mnoho autorsky volných českých knih (např. Švejka 1. a 2. díl, 3. a 4. díl) zase můžete stáhnout ze stránek Městské knihovny v Praze. Zkuste si stáhnout nějakého klasika a něco si v něm najít třeba pomocí programu AntConc.
V záhlaví příspěvku je konkordance slova thy v úplném díle Williama Shakespeara (program AntConc).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
[…] časem jsem ukázal, že si můžete v počítači vytvořit svůj vlastní korpus. Bude to sice korpus vytvořený na míru, na rozdíl od „profesionálních“ korpusů ale bude […]