
Každý obor má svá třaskavá témata. V překladatelské branži mezi ně patří téma „Může být Trados užitečný literárním překladatelům?“ Stačí, aby někdo nadhodil, že by se Trados (nebo jiný nástroj počítačem podporovaného překladu, CAT) dal použít i k překládání beletrie, a hned to od literárních překladatelů schytá. Jejich argument by se často dal shrnout slovy: „Beletrie se v Tradosu nepřekládá. Tečka.“ Inu, teď se vrhnou i na mě, protože chci ukázat, že by možná nástroje CAT mohly pomoci i jim a že paušální odmítání nástrojů CAT možná vychází z neznalosti těchto programů.
Nástroje CAT se samozřejmě nejlépe hodí na překlad věcných textů, v nichž se často opakují určitá slova, slovní spojení a věty a u nichž je třeba dodržet přísná pravidla a terminologii. Nástroje CAT překladatelům pomáhají vyhledáváním v překladových pamětech, terminologických databázích a „našeptávacích“ slovnících. Zároveň ale překladatelům nabízejí pracovní prostředí, které se obvykle liší od textového editoru. Překladatel tak vidí originál a překlad vedle sebe. To ve Wordu nemá. V CAT tak snadno může překlad srovnávat s originálem a navíc vyhledávat jak v originálu, tak v překladu. Díky tomu rychle zjistí, jak překládal to či ono slovo v předminulé kapitole.
Segmentace po odstavcích
A právě tady přichází první námitka odpůrců CAT: „Já ale pracuji s textem jako celkem, proto ho nemůžu mít nasekaný po větách.“ Nevím, jak v jiných CAT, ale v Tradosu si místo klasické segmentace po větách můžete nastavit segmentaci po odstavcích. Potom je struktura textu podobná jako v textovém editoru a možná pak už jde jen o zvyk.
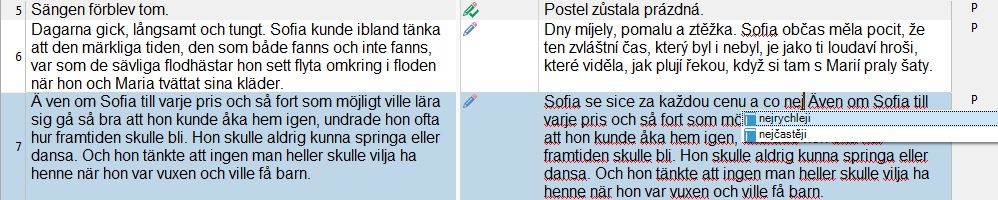
Obrázek. Odstavcová segmentace v programu Trados Studio 2015 s aktivní funkcí AutoSuggest (ukázka z knihy Henninga Mankella Eldens hemlighet)
Chápu, že na prostředí CAT si každý nezvykne. I ono paralelní dvoujazyčné zobrazení v CAT může některým překladatelům vadit, protože výchozí jazyk může při stylizaci cílového textu rušit, nebo je znervózňuje obrazovka plná všemožných oken, která neodpovídá dnes modernímu trendu „zenových“ řešení (viz např. textový editor Writemonkey) – přiznejme si to, Trados je v tomhle smyslu totální anti-zen. Nestálo by ale za to využít alespoň některých výhod CAT, alespoň v některých fázích práce na překladu? Třeba v okamžiku, kdy chci překlad důkladně srovnat s originálem. V tom případě můžu texty ex post spárovat („zarovnat“, „alignovat“), čímž získám ono přehledné paralelní zobrazení. Právě zarovnáním a srovnáním také odhalím, že jsem třeba někde vynechal celou větu. Mimochodem když jsem skenoval a alignoval několik starších literárních překladů, vzal za své mýtus o dokonalosti překladů vydaných před rokem 1989. Na překlepy a pravopisné chyby jsem narazil častěji, než jsem čekal, a výjimkou nebyla ani chybějící věta (a ne, na vině pravděpodobně nebyl cenzor ani nutnost zkrátit text z grafických důvodů).
CAT jako elektronický slovník / korpus
Dále můžeme překladové paměti vytvořené ze starších překladů používat podobně jako slovníky a korpusy, tedy jako referenční nástroj. Myslím, že by to mohli ocenit hlavně překladatelé z jazyků, pro které neexistují elektronické, případně vůbec žádné slovníky.
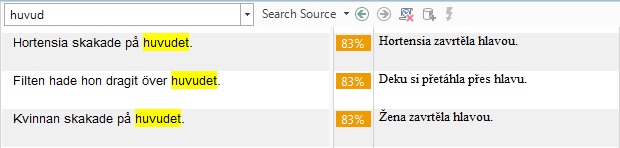
Obrázek. Konkordance – výsledek vyhledávání v překladové paměti (hledání švédského slova huvud, hlava)
Koneckonců paměť pro tyto účely můžeme vyrobit nejen ze svých vlastních překladů, ale i z překladů jiných překladatelů: z elektronických dokumentů, z naskenovaných knih nebo e-knih (v obou případech nejdřív vyrobíme běžný textový soubor). Já osobně bych se zcela jistě překladovou paměť snažil vyrobit z cizího překladu např. v situaci, kdybych měl přeložit film natočený podle literární předlohy, která existuje v českém překladu, a mým úkolem by bylo z překladu vycházet. Nebo kdybych měl překládat pokračování knižní série anebo televizního seriálu. Kdybych texty nedostal v elektronické podobě nebo by se nedaly pořídit jako e-knihy (bez ochrany DRM), pak bych si opatřil knihy tištěné. Originál i překlad bych naskenoval a převedl na text. To zabere několik desítek minut až několik hodin. Potom bych získaný text lehce opravil (důležité je hlavně to, aby věty nebyly rozetnuty vedví) a provedl bych zarovnání. A měl bych dodat, že překladové paměti se dají používat i mimo plnohodnotné programy CAT.
V souvislosti s jazyky, ze kterých se příliš často nepřekládá, dodávám, že paměť se dá vyrobit i z dvou textů přeložených z třetího jazyka. Řekněme, že mám český a indonéský překlad jedné a téže knihy původně napsané v některém třetím jazyce. Indonésko-českou nebo česko-indonéskou paměť vytvořím stejným způsobem, jako kdybych zarovnával překlad z první ruky.
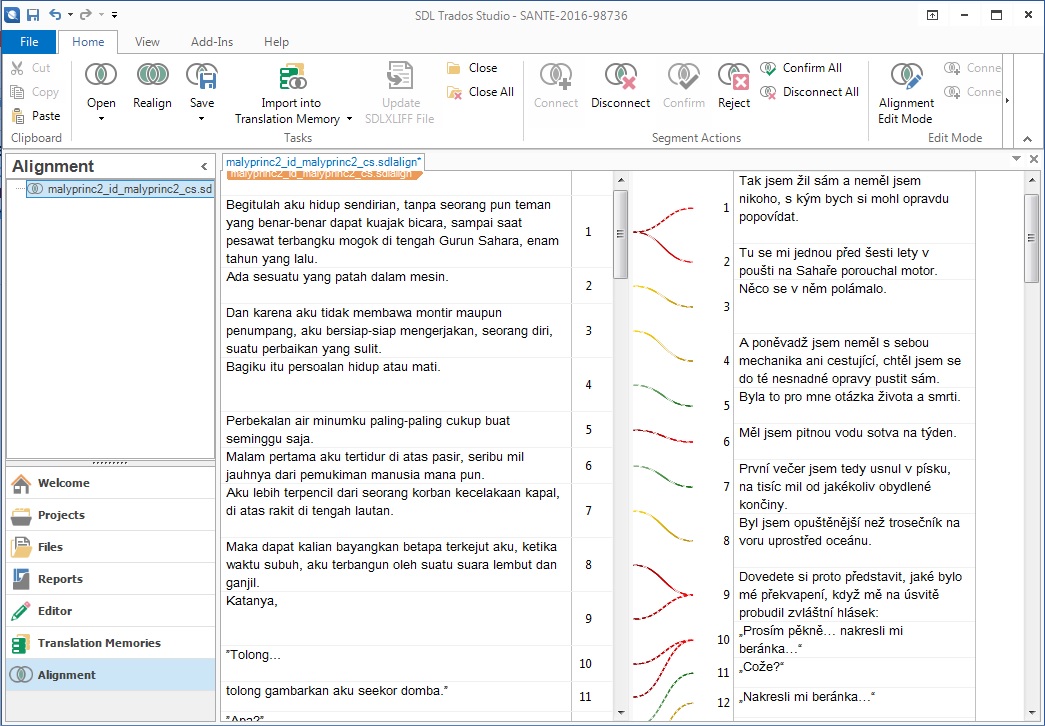
Obrázek. Zarovnání indonéského a českého překladu Malého prince Antoine de Saint-Exupéryho v programu Trados Studio 2015 (český překlad Zdeňka Stavinohová, indonéský překlad Henri Chambert-Loir)
Terminologická databáze
Pokud jde o terminologickou databázi (v Tradosu „termbase“), v ní můžeme mít v případě odborného překladu terminologický glosář, ale také do ní můžeme průběžně ukládat cokoliv užitečného, třeba často se opakující názvy, jména postav, slovní spojení… Když se takové slovo v daném segmentu vyskytne, Trados ho ve výchozím textu označí červenou úsečkou, slovo i s překladem zobrazí v příslušném „slovníkovém“ panelu vpravo nahoře, a když napíšeme první písmeno, našeptavač (AutoSuggest) nám slovo nabídne. A ať už našeptavač nabízí „oběhové hospodářství“, „Nizozemsko“ nebo třeba „Karel Veliký“, pomůže nám nejen zachovat jednotnost, ale navíc nám ušetří mnoho úhozů, za což nám poděkují i karpální tunely – podrobněji viz článek Jak vyzbrojit Trados na překlady pro EU. To platí i pro slova a slovní spojení, která našeptavač nabízí ze zvláštního slovníku a odjinud.
Ale zpět k odstavcové segmentaci. Jak už jsem řekl, její výhoda je v tom, že se zobrazení textu blíží zobrazení v klasickém textovém editoru. Nevýhodou je ovšem to, že program pak nabídne řešení z paměti jen sporadicky. – Při větné segmentaci to u beletrie taky nebude žádná sláva, ale nějaká ta shoda přece jen občas nastane u vět typu „Ano,“ odpověděla. O tyto shody nám však u literatury nepůjde a hlavním přínosem bude spíše paralelní zobrazení, vyhledávání v paměti a našeptavač.
Ohrožují nástroje CAT kreativitu?
Před časem proběhla na serveru ProZ diskuse na téma, jestli nástroje CAT ohrožují kreativitu. Většina diskutujících se shodla, že nikoliv, protože překladová paměť je jen nástrojem a záleží na uživateli, jak jí bude využívat. Osobně jsem toho názoru, že nástroje CAT můžou být velkým pomocníkem i u literárního překladu, ale že by je literární překladatelé ocenili více, kdyby programy více braly v úvahu jejich specifické potřeby.
Například si dokážu představit funkci, která by u přeloženého textu skryla originál a překlad zobrazila téměř jako v běžném textovém editoru (některé CAT nástroje tuto funkci mají). Nebo funkci, která by snadno přepínala segmentaci z větné na odstavcovou a zpět. Režim, kdy by program i při odstavcové segmentaci pracoval s jednotlivými větami. Anebo režim, kdy by překladatel pracoval v textovém editoru (nebo v rozhraní textový editor připomínajícím), v němž by ale měl rychlý přístup ke všem důležitým funkcím CAT: k vyhledávání v paměti, k našeptavači, k vyhledávání v paralelním zobrazení (v originálu i překladu).
Zkrátka kdyby programy CAT nabídly větší variabilitu uživatelského rozhraní a funkcí, možná by jim přišlo na chuť víc překladatelů včetně těch literárních. A možná by tak padly některé překážky, které objektivně či subjektivně tvoří mezi tvůrčími překladateli a nástroji CAT nepřekonatelnou bariéru. Pak bychom se ale měli připravit i na nové otázky v oblasti etiky, autorského práva apod. O tom ale někdy příště.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
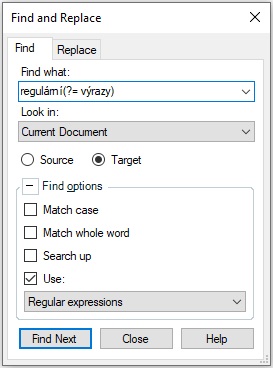{kind=link}
Komentář vložíte zde.
Chcete-li vložit komentář, musíte se přihlásit.