Když potřebujeme v rozdělaném překladu změnit slovo „geografie“ na „zeměpis“, snadno najdeme všechny výskyty prostým fultextovým vyhledáváním. Ale co když u některých postav potřebujeme změnit tykání na vykání, a proto potřebujeme najít všechny výskyty tykání? Není to hledání jehly v kupce sena? V některých případech nám může pomoci takzvané tagování nebo, chcete-li, značkování.
Tagování je proces, kterým procházejí profesionální jazykové korpusy. Ke každému slovu je přidána informace o jeho vlastnostech. Například v Českém národním korpusu má tvar stromem tag NNIS7—–A—–, který mimo jiné znamená, že to je podstatné jméno, které je mužského rodu neživotného, a sice v 7. pádu jednotného čísla. Ve Sketch Engine má stejný tvar jiný tag, k1gInSc7, znamená ale totéž (v tagu ČNK je navíc jen informace, že slovo nemá negativní předponu ne-).
Málokdo ví, že text si dnes může nechat otagovat i běžný uživatel, třeba právě překladatel, který chce najít výskyty určitého gramatického jevu. Vím o dvou možnostech, jak to udělat. Pokud znáte nějakou další, budu vděčný, když mi o ní napíšete.
1. Sketch Engine
První možností je předplatit si přístup ke korpusovému portálu Sketch Engine a vytvořit si z daného textu uživatelský korpus. V případě mnoha jazyků totiž Sketch Engine při kompilaci korpusu texty označkuje a zároveň lemmatizuje, tedy přiřadí ke slovům i informaci o základním tvaru: že například základní tvar od stromem je strom. Když potom chceme najít některou gramatickou kategorii, musíme se podívat do přehledu značek a vytvořit dotaz.
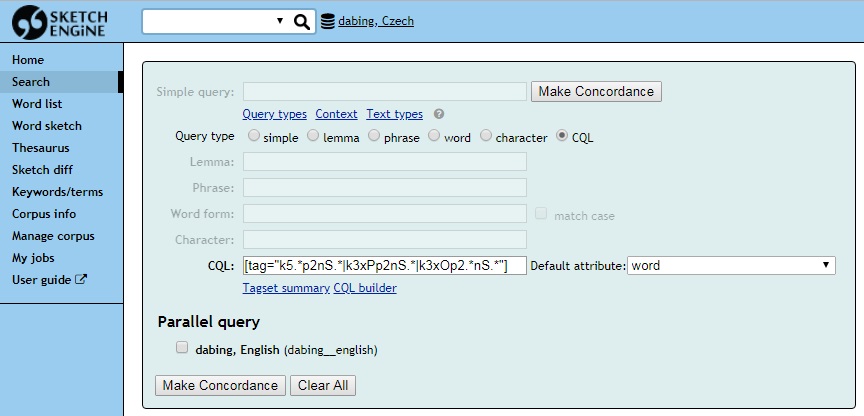
Řekněme, že hledáme výskyty tykání. To konkrétně znamená, že hledáme všechny tvary zájmena ty a tvůj a dále všechna slovesa ve druhé osobě jednotného čísla. Když se podíváme do přehledu tagů pro češtinu, poskládáme následující tři dotazy typu CQL.
| tvary zájmena ty | [tag=“k3xPp2nS.*“] |
| tvary zájmena tvůj | [tag=“k3xOp2.*nS.*“] |
| tvary slovesa ve 2. os. j. č. | [tag=“k5.*p2nS.*“] |
Když dotazy spojíme, můžeme do dotazu typu CQL zadat: [tag=“k5.*p2nS.*|k3xPp2nS.*|k3xOp2.*nS.*“] – viz obrázek v záhlaví. Výsledek hledání potom vypadá nějak takto. Jednotlivé položky si pak můžeme prohlédnout a v textu (v textovém procesoru) udělat potřebné úpravy.
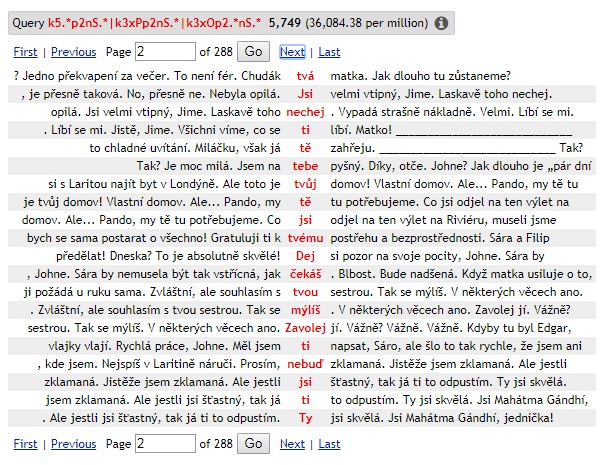
Obrázek. Odpověď na dotaz na portálu Sketch Engine: výskyty tykání v korpusu dabingové češtiny
Jediné, co bohužel v tuto chvíli nenajdeme, jsou hovorové tvary typu žes a řeklas, kde je tvar jsi zredukován na „koncovku“ -s. Tagování totiž probíhá automaticky a systém taguje na základě toho, co se naučil na trénovacích datech. No a protože se většinou učí na spisovných textech, kde se tyto výrazy prakticky nevyskytují, je malá pravděpodobnost, že je otahuje tak, jak bychom potřebovali. Kromě toho může tak jako u každého jiného tagovacího systému systém občas nastat chyba.
Pro úplnost: dotaz na vykání by vypadal takto: [tag=“k5.*p2nP.*|k3xPp2nP.*|k3xOp2.*nP.*“]
2. UDPipe
Druhou možností, o které vím, je systém UDPipe, který vznikl na Ústavu formální a aplikované lingvistiky MFF UK.
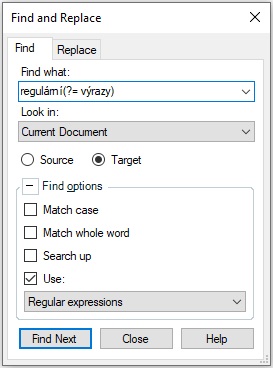
V tomto případě na vstupní stránce vybereme jazyk, nahrajeme text a počkáme na jeho zpracování. Zpracovaný text si potom můžeme stáhnout do počítače a otevřít v textovém editoru, který podporuje klasické regulární výrazy, např. Notepad++. Tento text není úplně nejpřehlednější, protože má podobu vertikály: každé slovo je na samostatném očíslovaném řádku a za ním následuje lemma a doplněné značky.
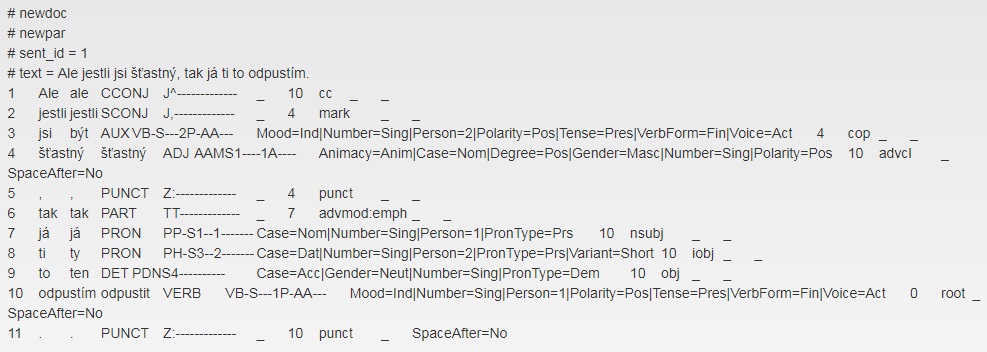
Obrázek. Tagovaný a lemmatizovaný výstup z UDPipe
Když chceme najít výskyty hledaného jevu, opět se musíme podívat do přehledu značek. V případě češtiny vystačíme se značkami Českého národního korpusu, které jsou přehledně uvedeny zde. Pokud tedy hledáme výskyty tykání, vyjdou nám tyto tři dotazy:
| tvary zájmena ty | \tty\tPRON\tP..S |
| tvary zájmena tvůj | \ttvůj\tDET\tP…..S |
| tvary slovesa ve 2. os. j. č. | \tV..S…2 |
Když dotazy opět spojíme, můžeme v programu Notepad++ zadat tento vyhledávací dotaz: \tV..S…2|\tty\tPRON\tP..S|\ttvůj\tDET\tP…..S
I v tomto případě bohužel musíme počítat s tím, že nenajdeme stažené tvary typu tos a chtěls.
Pro úplnost opět doplním dotaz pro hledání výskytů vykání: \tV..P…2|\tty\tPRON\tP..P|\ttvůj\tDET\tP…..P
Tagování a nástroje budoucnosti
Ten, kdo pracuje s jazykem, jistě najde i mnoho dalších využití tagování. Jistě jej ocení mnozí studenti, kteří píší seminární práci nebo diplomovou práci, ale dokážu si představit, že tagování může pomoci i při redakční práci nebo při studiu cizích jazyků: řekněme, že v chorvatštině nedokážu rozluštit slovo gradova. Co je to za tvar? Jaký je základní tvar, gradov? Proto ho zadám i s celou větou do UDPipe, vyberu chorvatštinu a už za okamžik vím, že jde o 2. pád množného čísla slova grad, tedy město.
Jak vidíme, už dnes existují technologie, o kterých by se nám ještě nedávno mohlo jen zdát. Teď si můžeme nechat zdát o tom, že časem budou součástí jazykových nástrojů, jako jsou například nástroje počítačem podporovaného překladu (CAT). Program by náš překlad průběžně tagoval a lemmatizoval, takže bychom v překladu mohli hledat stejným způsobem jako v korpusu, tedy i podle základního tvaru slova a podle gramatických kategorií. A například audiovizuální překladatelé by ocenili, kdyby tyto nástroje zvládaly i nespisovný jazyk, aby mohli vyhledat například všechna slovesa v 1. osobě množného čísla zakončená na -m, například hrajem, začnem. Prozatím modely pro češtinu UDPipe považují začnem za 7. pád podstatného jména začno nebo začn – zřejmě se v trénovacích korpusech s ničím podobným ještě nesetkaly.
Důležité upozornění ke korpusovým dotazům: všechny uvozovky musí být rovné.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}