Chcete si vytvořit vlastní korpus, ve kterém budete moci zjišťovat, jak se jazyk chová, a hledat i podle základních tvarů slov a gramatických kategorií? Např. všechny tvary slova dobrý nebo všechna slovesa začínající předponou roz- v minulém čase? Nejsnazším řešením je komerční, ale finančně dostupná služba Sketch Engine.
Před časem jsem ukázal, že si můžete v počítači vytvořit svůj vlastní korpus. Bude to sice korpus vytvořený na míru, na rozdíl od „profesionálních“ korpusů ale bude mít jednu velkou slabinu: nebude lemmatizovaný a označkovaný. Znamená to, že v něm nebudete moci hledat na základě „slovníkového“ tvaru slova a že řada funkcí, včetně výpočtu kolokací, bude takříkajíc rozředěna.
Naštěstí existuje jedno snadné řešení. Jmenuje se Sketch Engine a je to vlastně takový korpusový hypermarket, ve kterém nechybí velké oddělení pro kutily: server Sketch Engine nabízí jednak pěknou řádku hotových korpusů v 80 jazycích, jednak možnost vytvořit si korpus vlastní. K práci s korpusy a k užitečným funkcím Sketch Enginu se časem vrátíme, teď se ale podrobněji podívejme na tvorbu uživatelských korpusů.
Jak vytvořit jednojazyčný korpus
Jednojazyčný korpus můžeme ve Sketch Enginu vytvořit dvěma základními způsoby: jednak nahráním konkrétních textů, jednak postahováním textů z internetu na základě klíčových slov.
Nejprve tedy nahrání konkrétních textů. Můžeme to udělat několika způsoby: text můžeme překopírovat do příslušného okna, můžeme nahrát soubor či soubory z počítače (nahráváme-li víc souborů, zabalíme je např. do souboru ZIP), anebo zadat URL (např. odkaz na webovou stránku s textem). Následně zadáme, že chceme korpus zkompilovat. Korpus se automaticky zpracuje a zanedlouho jej můžeme začít používat stejně jako kterýkoli z hotových korpusů.
Při automatickém zpracování je v případě mnoha jazyků text označkován a lemmatizován. Právě díky tomu pak můžeme v českém korpusu najít například všechna slovesa začínající předponou roz- (a navíc třeba ve tvarech minulého času). Informaci o tom, u kterých jazyků při zpracování probíhá slovnědruhové značkování, získáme na této stránce ve sloupci POS. U většiny z nich zároveň probíhá i lemmatizace (tzn. zadáme tvar dobrý a korpus najde i lepší a nejlepšími), ale ne u všech (neprobíhá např. u arabštiny, hebrejštiny nebo maďarštiny). To už je třeba ověřit konkrétním hledáním ve vytvořeném korpusu.

Obrázek. Okno pro nahrání textů – zde jsem zadal adresu souboru s kompletním dílem Williama Shakespeara na serveru Project Gutenberg
Podrobněji o vytváření jednojazyčného korpusu nahráním textů
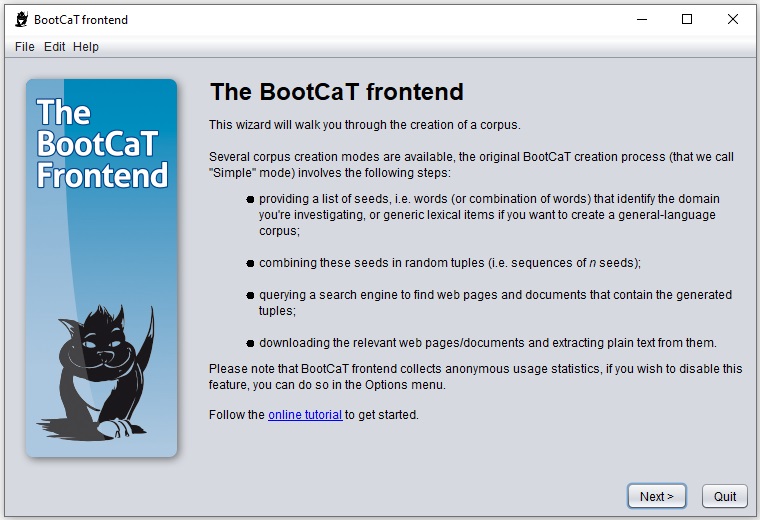
Jak už jsem řekl, druhou možností je nechat si korpus postahovat z webu na základě klíčových slov pomocí funkce WebBootCaT. Možná znáte nástroj BootCaT, který vám na základě několika zadaných klíčových slov postahuje z webu texty, které obsahují kombinaci (tzv. n-tici, anglicky tuple) zadaných slov. Funkce WebBootCaT funguje podobně. Zadáte klíčová slova, korpusový manažer najde odkazy na stránky, kde se vyskytují jejich kombinace, vy seznam těchto stránek můžete projít a podle potřeby některé odstranit. (Místo klíčových slov také můžete zadat odkazy na konkrétní stránky.) Manažer potom data stáhne a zpracuje – a vy můžete s korpusem opět pracovat stejně jako s kterýmkoli korpusem z nabídky Sketch Enginu. Když klíčová slova (případně stránky) vyberete chytře a zadáte jich dost, získáte skutečně korpus šitý na míru.

Obrázek. Funkce WebBootCaT a příprava anglického korpusu textů o slonech
Podrobněji o funkci WebBootCaT
Jak vytvořit paralelní korpus
Kromě jednojazyčného korpusu si můžete vytvořit i korpus dvoujazyčný, paralelní. Metod, jak takový korpus vytvořit, nabízí Sketch Engine několik, překladatel ale nejspíš využije možnost nahrát soubor překladové paměti (TMX), kterou buď vyexportuje z nástroje počítačem podporovaného překladu (CAT), nebo vyrobí pomocí samostatného zarovnávače (aligneru). Nahrané texty se zpracují a potom můžete vyhledávat buď v každém jazyce zvlášť, anebo dvoujazyčně.
 Obrázek. Paralelní konkordance z česko-baskického korpusu vytvořeného nahráním souboru TMX (vytvořeného z 2. kapitoly Malého prince Antoine de Saint-Exupéryho): v češtině je možné vyhledávat na základě lemmatu, zde beránek (baskicky arkume)
Obrázek. Paralelní konkordance z česko-baskického korpusu vytvořeného nahráním souboru TMX (vytvořeného z 2. kapitoly Malého prince Antoine de Saint-Exupéryho): v češtině je možné vyhledávat na základě lemmatu, zde beránek (baskicky arkume)
Podrobněji o vytvoření parelelního korpusu
I v tomto případě Sketch Engine texty dokáže v řadě jazyků označkovat a lemmatizovat, takže následně můžete hledat i podle základních tvarů slov a gramatických kategorií.
Kromě konkordancí můžete v korpusech samozřejmě hledat i kolokace a celou řadu dalších věcí, např. klíčová slova, kolokační profily slov (funkce „word sketches“) nebo slova podobná (funkce „thesaurus“). Tyto funkce si ukážeme v některém z příštích příspěvků. Myslím ale, že překladatelé si už teď velmi dobře dokážou představit, v čem všem jim uživatelské korpusy mohou pomoci.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Komentář vložíte zde.
Chcete-li vložit komentář, musíte se přihlásit.