
Pustil jsem se do tvorby glosáře / terminologické databáze, která by měla pomoct překladatelům jedné neziskovky, která se zabývá Tibetem. A protože je úplně jedno, jestli sestavujete glosář tibetských reálií nebo bezpečnosti jaderných elektráren, rozhodl jsem se, že svůj postup stručně sepíšu, protože by mohl přijít vhod nejen mnoha překladatelům a projektovým manažerům, ale také spoustě tlumočníků.
Překládám už pár pátků pro Evropskou komisi a díky její terminologické databázi IATE vím, o kolik je snazší překládat texty plné nejrůznějších termínů, když máte po ruce kvalitní glosář / terminologickou databázi, kterou navíc můžete vložit do programu počítačem podporovaného překladu (CAT). U každé věty vás pak program upozorní, že to či ono slovo je v terminologické databázi obsaženo, a v samostatném okénku vám ukáže jeho ekvivalent. Ještě déle spolupracuji s jednou organizací, která se zabývá tibetskou současností a minulostí, a proto vím i to, že při překladu textů o Tibetu překladatel narazí na pěknou řádku slov, která by se také dala považovat za termíny. A pokud nejde o člověka znalého problematiky, překlad většinou nedopadne moc dobře.
Proto jsem si řekl, že se pokusím vytvořit anglicko-český glosář / terminologickou databázi nejčastějších termínů, které se vyskytují v textech o Tibetu a Tibeťanech. Půjde tedy o nejrůznější reálie, vlastní jména ve správném českém přepisu (osobní i geografická), ale i některé časté termíny z oblasti buddhismu, politiky, státní správy a lidských práv.
Potřeboval jsem tedy 1) najít kandidáty na termíny, které do glosáře zahrnu, 2) a doplnit k nim ekvivalenty: některé znám z hlavy, jiné jsem musel ověřit nebo najít.
Jaké prameny jsem využil?
Nejdřív jsem samozřejmě shromáždil klasické zdroje terminologie v tištěné podobě, v nichž jsem ale vytipoval jen ty opravdu nejdůležitější termíny – zpracovával jsem koneckonců glosář, a ne obsáhlý slovník. Využil jsem konkrétně:
- Slovníkové, encyklopedické a referenční publikace: např. Josef Kolmaš: Malá encyklopedie tibetského náboženství a mytologie nebo Josef Kolmaš: Slovník tibetské literatury,
- Slovníčky otištěné v publikacích o Tibetu, např. slovníček tibetských reálií v Žagabpových Dějinách Tibetu nebo soupis tibetských osobních jmen otištěný v Kolmašově knize Pojednání o věcech tibetských.
Dále jsem vyšel z existujících glosářů, které jsem v minulosti sestavil buď já, nebo jiní překladatelé, kteří pro neziskovku překládali.
Hodně mi pomohla i Wikipedie, ve které jsem si vyhledal jednak konkrétní hesla, jednak jsem se nechal vést portálem Tibet (v české i anglické verzi).
A potom začala ta nejzajímavější fáze: hledání termínů a klíčových slov v autentických textech. Konkrétně jsem si dal dohromady texty, které jsem měl v elektronické podobě nebo jsem je do ní mohl převést (pomocí optického rozpoznávání znaků, OCR), tedy tematicky relevantní články a celé knihy. Obrovským pomocníkem byly korpusy, konkrétně korpusový portál Sketch Engine – tedy přesněji řečeno: ono by to bez korpusů vůbec nešlo. A hlavně to vám v tomto článku chci ukázat.
Sketch Engine totiž nabízí jednak celou řádku hotových korpusů, jednak možnost vytvořit si korpus uživatelský. A když si vytvoříte svůj vlastní korpus – v mém případě korpus textů o Tibetu –, můžete si ho srovnat s vybraným referenčním korpusem a na základě toho zjistit, která slova a slovní spojení jsou pro váš korpus charakteristická. A právě tímto způsobem snadno najdete kandidáty na termíny do terminologické databáze.
Já jsem měl texty jednak v angličtině, jednak v češtině. A tak jsem si na portálu Sketch Engine nechal spočítat klíčová slova jednak pro češtinu, jednak pro angličtinu. Je to jednoduché: jakmile máte na portálu vytvořený uživatelský korpus, stačí kliknout na volbu Keywords/terms a portál během chvilky vytvoří seznam jednoslovných a víceslovných klíčových slov. Toto je ukázka několika klíčových slov z dalajlamovy autobiografie Freedom in Exile (Svoboda v exilu).
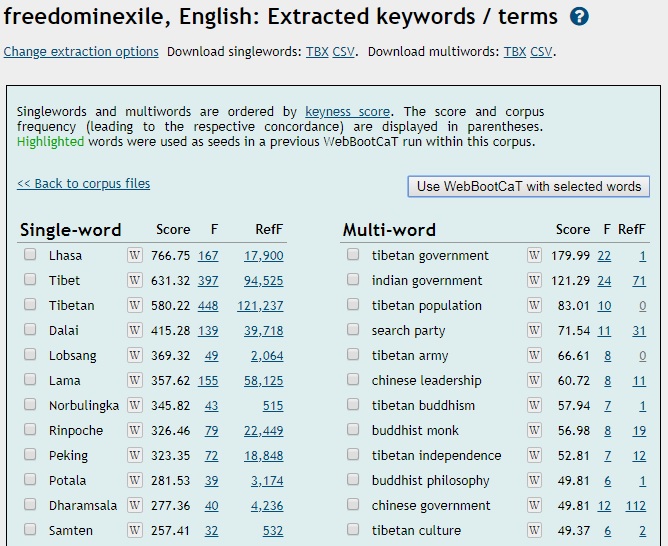
Česká verze klíčových slov ze stejné knihy (v překladu Josefa Kolmaše) vypadala takto:

Už tady vidíme, že se do glosáře nabízí například dalajlama (anglicky Dalai Lama), tedy slovo, ve kterém se často chybuje (v češtině se „lama the beast“ i „lama the priest“ píše stejně, tedy s krátkým a, a proto se píše krátce i dalajlama, navíc je počáteční d malé, protože nejde o vlastní jméno, ale o titul), potom například název paláce dalajlamů Potála (tentokrát s dlouhým á, anglicky Potala) nebo search party (česky vyhledávací skupina).
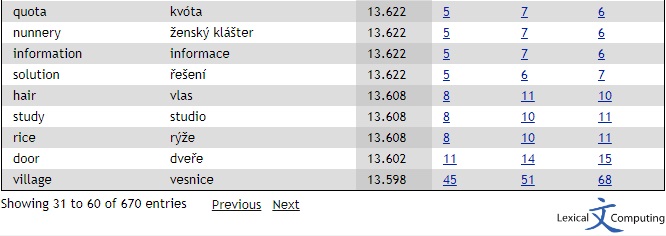
Některé texty jsem měl jak v originálu, tak v překladu, například už zmíněnou dalajlamovu autobiografii. A tak jsem pomocí speciálního programu (aligneru) z originálu a překladu vytvořil paralelní korpus / překladovou paměť. Tento soubor jsem nahrál na portál Sketch Engine a nechal jsem si vypočítat dvoujazyčný přehled klíčových slov. Sice v něm bylo mnoho slov, která rozhodně do terminologické databáze nepatřila (např. sever, sympatie, teorie), ale i tady jsem našel ledacos, co by mě zřejmě jinak nenapadlo, např. nunnery – ženský klášter.
Jak termíny zpracovávám
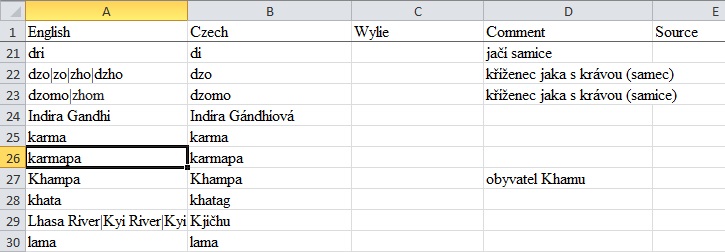
Ze všech těchto seznamů kandidátů jsem vybral termíny / klíčová slova, která jsem považoval za užitečná, a tato slova jsem vložil do tabulek v Excelu. Tam jsem si kromě sloupců pro angličtinu a češtinu vytvořil i sloupec pro případnou vysvětlivku, informaci o zdroji, a také pro případný ekvivalent v tibetštině (jednak v tibetském písmu, jednak v transliteraci), čínštině (v čínských znacích a v pchin-jinu) a latině (pro rostliny a živočichy). V Excelu mi navíc mnohdy pomohla funkce SVYHLEDAT nebo filtrování.
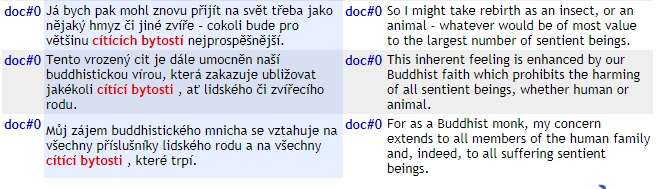
Při hledání ekvivalentů mi posloužily klasické dvoujazyčné konkordance na portálu Sketch Engine – zde například vyhledávám ekvivalent spojení cítítí bytost v dvoujazyčném korpusu vytvořeném z originálu a překladu už zmíněné knihy:
V tuhle chvíli má můj glosář / terminologická databáze 764 položek – tak velká je hlavně kvůli vlastním jménům. Některé položky jsou navíc duplicitní a vymazat bude třeba i některá jména, která se v glosáři ocitla spíše náhodou. V další fázi bych také rád zapojil lidi, kteří mají k terminologii co říct, aby potvrdili správnost některých ekvivalentů a doplnili další termíny. Podstatné je ale to, že ve kterékoli fázi se dá z excelovských souborů vytvořit terminologická databáze pro programy CAT (podrobnější informace k vytvoření dvoujazyčného korpusu a k převedení excelovské tabulky na terminologickou databázi najdete v mé knize Technologie ve službách překladatele).
Mimochodem podobným způsobem si glosář může připravit i tlumočník, který se připravuje na konferenci nebo jednání. Stačí, když si z podkladů sestaví korpus, ten nahraje na Sketch Engine a nechá si vygenerovat přehled klíčových slov / termínů. A možná by se tyto nástroje daly využít při tvorbě rejstříků k naučným publikacím.
Tvoříte glosáře podobným způsobem i vy? Vyzkoušeli jste Sketch Engine? Budu rád, když mi dáte vědět.
O vytvoření korpusu ve Sketch Engine jsem psal v tomto článku.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Existuje nejaký blbuvzdorný návod na export/import IATE do MultiTermu? Snažila som sa postupovať podľa návodu na oficiálnej stránke, ale nedostala som sa ani cez prvý krok…
IATExtract je trochu náladový, takže někdy odmítá spolupráci, ale nakonec vždycky export provede. Někdy pomůže, když to vyzkoušíte na různých počítačích. Celý postup jsem popsal v knížce Technologie ve službách překladatele, ale v podstatě jde jen o kombinaci IATExtract a Glossary Converteru.