Ač by se podle názvu mohlo zdát, že v Českém národním korpusu najdeme jen české texty, opak je pravdou. ČNK je dnes už pořádně velká rodinka korpusů, mezi nimiž najdeme i paralelní korpus InterCorp (dnes je v něm kromě češtiny 39 jazyků), ale také obří korpusy dalších jazyků, především webové korpusy pro tyto jazyky: DE, EN, ES, FI, FR, HU, IT, NL, PL, PT, RU, SK, ZH. Ukažme si hlavní možnosti vyhledávání v anglických korpusech. Analogicky si odvodíte i postup pro korpusy dalších jazyků.
V anglických i všech ostatních korpusech se obecně vyhledává stejně jako v těch českých, jen je třeba mít na paměti, že jsou jinak označkovány (a že některé označkovány nejsou). Proto se na slovní druhy budeme dotazovat jinými tagy. Ne, nebojte se, vlastně to vůbec není složité. Stačí si osvojit pár druhů dotazů a mít při ruce přehled tagů. Potom můžete z anglického korpusu získat totéž co z českého, například přehled kolokací.
Základní druhy vyhledávání
Základní druhy dotazů jsou jednoduché. V rozhraní Českého národního korpusu KonText zvolte například anglickou složku korpusu InterCorp (InterCorp v9 – English) a zkuste si různé druhy zadání dotazu.
- Typ zadání Slovní tvar najde přesně zadaný tvar a nic jiného, např. bear najde zase jen a jen bear (v některých případech jako podstatné jméno, v jiných jako sloveso).
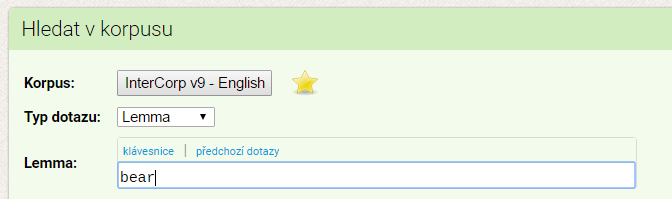
 Typ zadání Lemma najde všechny tvary zadaného základního („slovníkového“) tvaru slova, např. bear najde i bears (jako podstatné jméno i jako sloveso), bearing, born nebo borne. (Když nezadáte základní tvar, korpus nenajde nic.)
Typ zadání Lemma najde všechny tvary zadaného základního („slovníkového“) tvaru slova, např. bear najde i bears (jako podstatné jméno i jako sloveso), bearing, born nebo borne. (Když nezadáte základní tvar, korpus nenajde nic.)- Pomocí typu zadání Fráze můžete zadat více po sobě jdoucích slov, např. polar bear. Je to podobné jako typ zadání Slovní tvar: ve výsledcích najdete zadaná slova přesně v zadaných tvarech.
Můžete použít i zástupné znaky. Je jich celá řada, ale pro začátek vystačíte s kombinací .* (tečka bezprostředně následovaná hvězdičkou), což znamená „žádný znak nebo libovolný počet libovolných znaků“. Touto „královskou kombinací“ mnohdy obejdete mnohem složitější zadání. Zkuste zadat (zadání typu Fráze) třeba look.* forward.
Vyhledávání s využitím tagů
Teď se podívejme, jak jsou slova označkovaná. Vybereme typ dotazu Lemma a zadáme bear. Když se zobrazí konkordance, nahoře klikneme na Zobrazení > Atributy, struktury a metainformace. Zaškrtneme volbu lemma a tag. Nakonec stiskneme enter nebo klikneme dole na modré tlačítko. Tím se v konkordanci u každého hledaného slova zobrazí lemma (základní tvar slova) a tag (morfologická značka).

Obrázek. Konkordance slova (lemmatu) bear se zobrazením lemmatu a tagu
Vidíme, že slovesa jsou označkovaná jako VB, substantiva jako NN (v některých případech chybně – s tím se ale musíme smířit, protože dosáhnout 100% správnosti je nereálné). Případně následuje další upřesňující písmeno. Úplný přehled značek je na str. 7 tohoto dokumentu – od značek použitých pro české korpusy se tyto značky velmi liší. Není divu: čeština jako flektivní jazyk potřebuje značek mnohem víc.
Když máme při ruce přehled použitých značek, můžeme je použít k zadání dotazu. Tentokrát vybereme typ zadání CQL.
Příklad první: hledáme tvary slova bear následované substantivem
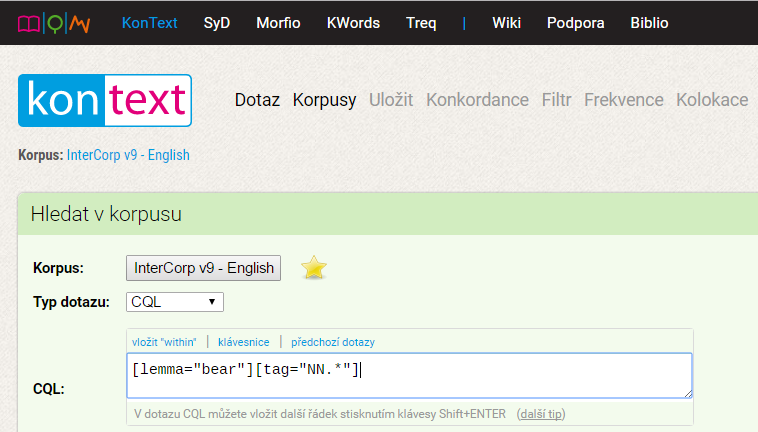
Zadáme: [lemma=“bear“][tag=“NN.*“]
(Technická poznámka: pokud budete zadání kopírovat z tohoto článku, vždy opravte oblé uvozovky na rovné.)
Ve výsledcích vidíme např. spojení bear witness, bear fruit.
Příklad druhý: hledáme výskyty substantiva bear
Zadáme: [lemma=“bear“ & tag=“NN.*“]
Tedy hledáme lemma, které je zároveň substantivem. Tečka a hvězdička následuje po NN proto, abychom pokryli nejen značku NN, ale i NNS (substantivum v plurálu).[1]
Příklad třetí: hledáme sloveso + přivlastňovací zájmeno + way + through
Zadáme: [tag=“VB.*“][tag=“PP\$“][word=“way“][word=“through“]
Upozorňuji, že v tagu pro přivlastňovací zájmeno musíme před symbol $ napsat zpětné lomítko (ač to ze soupisu tagů není zřejmé). Toto je také jediný případ, kdy se mi stalo, že se program zadání bránil, nakonec ale výsledky přece jen zobrazil.
Příklad čtvrtý: hledáme sloveso single + nula až dvě libovolná slova + out
Zadáme: [lemma=“single“ & tag=“VB.*“][]{0,2}[word=“out“]
{0,2} znamená „nula až dvě opakování předchozího prvku“, tedy nula až dvě opakování pozice (slovo, interpunkční znaménko, číslo atd.), protože hranaté závorky označují jednu pozici.
Korpusy Aranea a ukWaC
Do této chvíle jsme hledali v anglické části korpusu InterCorp, která má ve verzi 9 velikost necelých 120 milionů slov. Jak už jsem ale naznačil, v ČNK jsou i obrovské jednojazyčné korpusy sestavené z textů postahovaných z webu: ukWaC a Aranea (několik geograficky vymezených verzí vždy ve dvou velikostech). Korpusy Aranea jsou označkovány stejně jako InterCorp, ale některé značky použité v korpusu ukWaC jsou odlišné (hlavně u sloves: VV místo VB) – najdete je tady.
Přehled všech korpusů v rámci ČNK najdete tady. U jednotlivých korpusů najdete odkazy vedoucí na seznam použitých značek, tzv. tagset. Pokud tedy chcete vyhledávat např. v německých korpusech, najděte si nejprve příslušný tagset. Případně si nejdřív tagy zobrazte v konkordanci, ať víte, jak vypadají. V některých jazycích jsou velmi jednoduché, v jiných mají složitější strukturu.
Nezapomeňte se také seznámit s jednotlivými korpusy, protože při vyhledávání v korpusu je důležité vědět, co přesně do něj bylo zařazeno a jak je velký.
Podrobnější informace najdete ve wiki Českého národního korpusu
Technická poznámka: redakční systém tohoto blogu automaticky mění rovné uvozovky na „kudrnaté“, do ČNK je ale třeba zadávat uvozovky rovné. Proto budete-li dotazy z tohoto článku kopírovat do dotazu v ČNK, nezapomeňte uvozovky změnit na rovné (stačí stisknout klávesu s uvozovkami).
[1] Přesnější by v tomto případě bylo zadání ve tvaru [lemma=“bear“ & tag=“NN|NNS“], překladatel ale většinou vystačí se zadáními obsahujícími tečku a hvězdičku.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Komentář vložíte zde.
Chcete-li vložit komentář, musíte se přihlásit.